Problema
Un proyecto personal para juntar lo que la mayoría de los demos de IA dejan afuera: orquestación de verdad, una caché real y un frontend liviano. El planteo era acotado — poder consultarle al asistente sobre un tema de noticias y obtener una respuesta coherente, anclada en datos extraídos de la web — pero la idea era conectarlo como lo entregaría en producción.
Enfoque
Tres capas, cada una elegida por su lugar en el stack, no por su hype:
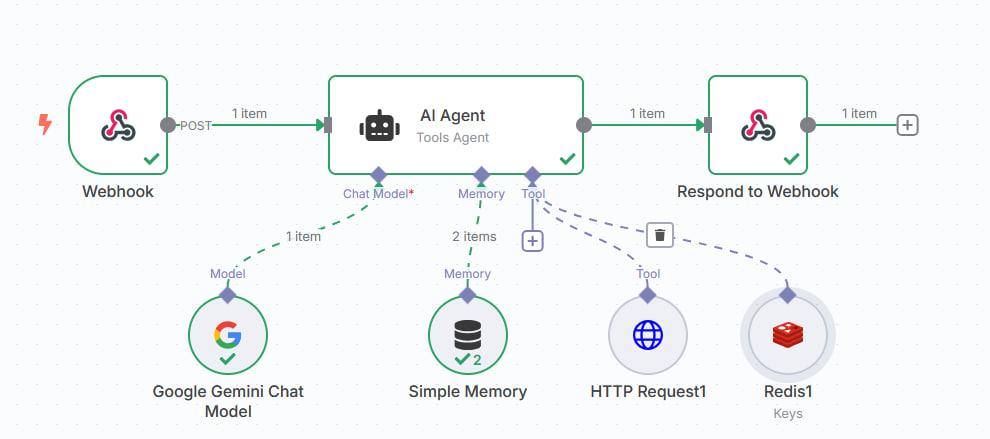
- Orquestación (n8n) — el workflow de IA vive en n8n, no en código de aplicación. Un webhook recibe la pregunta del usuario, un AI Agent (Tools Agent) de n8n la enruta a través de un chat model, un store de memoria y una herramienta HTTP-request que consulta la caché FastAPI. El agente emite una respuesta final por un webhook de respuesta. La captura muestra el grafo completo: Webhook → AI Agent (Tools Agent) conectado a Google Gemini Chat Model, Simple Memory, HTTP Request y Redis como key store → Respond to Webhook.
- Datos + caché (FastAPI + Redis) — una API REST FastAPI sirve los datos de noticias extraídos eficientemente desde una capa Redis. Redis acá no es solo memoria de sesión — es el plano de datos calientes contra el que el agente pega vía HTTP Request.
- Frontend (SvelteKit) — un GUI de asistente virtual en SvelteKit le habla al webhook de n8n. Liviano, rápido, sin el peso de bundle de React.
- Despliegue (Docker Compose) — el stack completo se ejecuta en contenedores desde un solo compose file. Un comando levanta n8n, FastAPI, Redis y el frontend SvelteKit en un único host.
Resultado
El patrón arquitectónico: orquestación fuera del código de aplicación (n8n), datos calientes detrás de una caché real (Redis), frontends finos y especializados (SvelteKit) y un despliegue de un comando que asume la operación end-to-end.