Problem
A personal project to put together what most AI demos leave out: proper orchestration, an actual cache, and a thin frontend. The brief was small — let me ask the assistant about a news topic and get a coherent answer grounded in scraped data — but the goal was to wire it the way I’d ship it in production.
Approach
Three layers, each picked for its place in the stack rather than its hype:
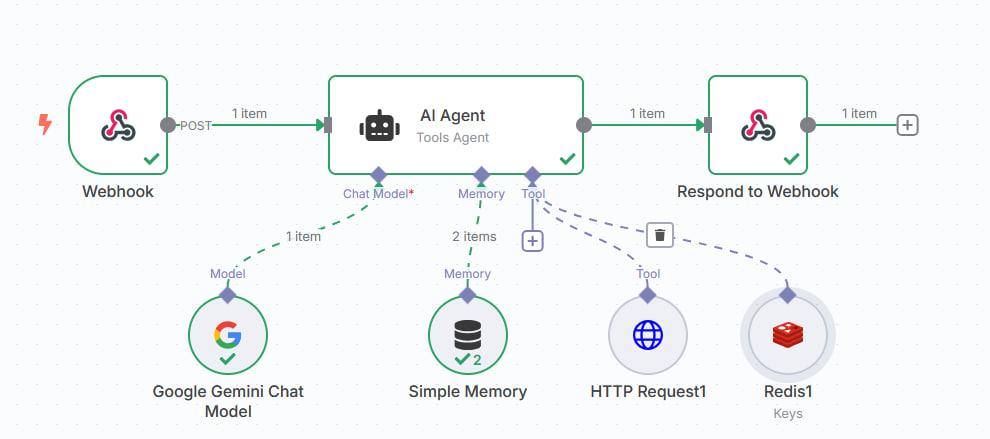
- Orchestration (n8n) — the AI workflow lives in n8n, not in application code. A webhook receives the user’s question, an n8n AI Agent (Tools Agent) routes it through a chat model, a memory store, and an HTTP-request tool that reaches the FastAPI cache. The agent emits a final answer back through a response webhook. The screenshot shows the full graph: Webhook → AI Agent (Tools Agent) wired to Google Gemini Chat Model, Simple Memory, HTTP Request, and Redis as a key store → Respond to Webhook.
- Data + cache (FastAPI + Redis) — a FastAPI REST API serves scraped news data efficiently from a Redis layer. Redis isn’t just session memory here — it’s the warm-data plane the agent calls into through HTTP Request.
- Frontend (SvelteKit) — a virtual assistant GUI in SvelteKit talks to the n8n webhook. Light, fast, no React bundle weight.
- Deploy (Docker Compose) — the whole stack containerizes into one compose file. One command brings up n8n, FastAPI, Redis, and the SvelteKit frontend on a single host.
Outcome
The architecture pattern: orchestration outside application code (n8n), warm data behind a real cache (Redis), thin specialized frontends (SvelteKit), and a one-command deploy that owns the operational story.